

Git est utilisé très largement aujourd'hui, mais de mon expérience, j'ai l'impression que c'est aussi un outil relativement mal compris et mal utilisé. En particulier j'aimerais revenir sur deux commandes souvent interchangé : merge et rebase.
Qu'est-ce qu'un merge ?
Merge (en français "fusion") est une commande qui vise à fusionner l'historique de deux branches, on part de deux branches et on finit avec une seule branche.
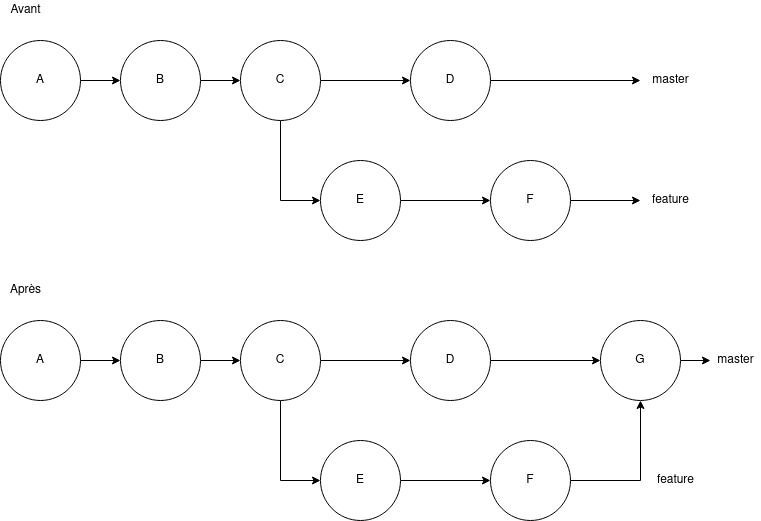
Comme illustré sur le schéma, si on se place sur la branche master, et qu'on appelle la commande git merge feature, on va créer un commit de merge qui va regrouper l'ensemble du contenu des commits exclusifs de la branche feature pour les appliquer sur le dernier état de la branche merge.
Globalement si vous m'avez bien suivi, faire un merge implique qu'on considère que la branche sur laquelle on fusionne reçoit des modifications extérieures (la branche feature vient modifier master). On notera aussi que le commit de merge va venir en quelque sorte poluer l'historique si on ne fait rien avant de merge.
À noter que ce commit n'existerait pas si la branche feature partait non pas du commit C, mais du commit D, en effet dans ce cas aucun commit de la branche master ne serait pas inclue dans la branche feature, donc aucun intérêt de créer un commit pour gérer la fusion : il n'y aura pas de fusion, uniquement un déplacement des commits de la branche feature à la branche master. C'est ce qu'on appelle le "fast forward".
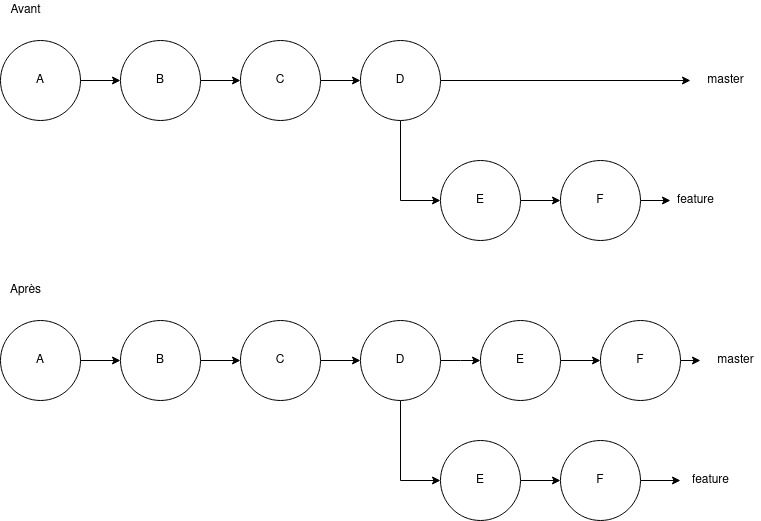
Il y a globalement un seul cas où le merge est le bon choix : quand vous voulez partager avec le reste de l'équipe votre travail. Le nom de la commande l'indique bien (merge/fusion), cette commande est faite pour que votre travail que vous avez fait dans votre coin soit ajouter au travail collectif.
Qu'est-ce qu'un rebase ?
Un rebase va changer la racine de l'historique d'une branche. Une branche démarre toujours à partir d'un commit donné, si on effectue un rebase d'une branche par rapport à une autre, on va demander à git de considérer qu'on a tiré notre branche à partir d'un autre commit.
J'imagine que ça doit faire tilte dans votre tête du fait que c'est considérer comme une mauvaise chose de réécrire un historique, et c'est bien si c'est le cas, mais un rebase est une réécriture "naturelle" dans le cycle de vie de votre branche, car normalement un rebase ne doit jamais impliquer de changer l'historique de la branche partagé avec vos collègues (typiquement votre master/main).
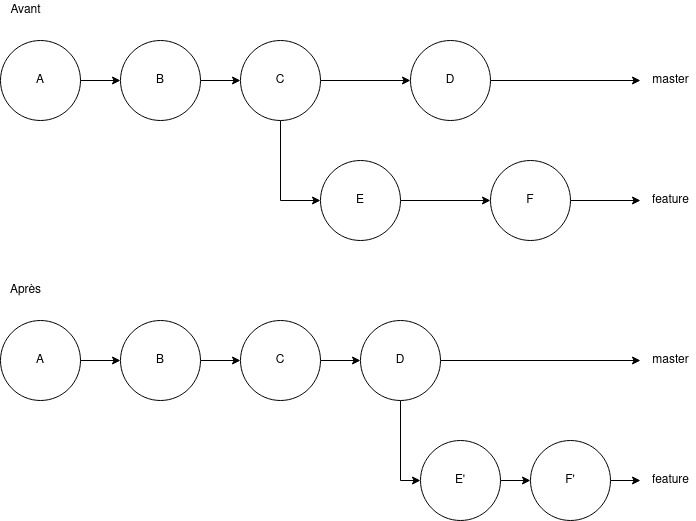
Il y a principalement deux cas où le rebase est le bon choix :
- vous êtes sur une branche qui est partagée avec d'autres collègues, et vous voulez récupérer leur travail : dans ce cas ça revient à se mettre à jour par rapport à ce qu'ils ont fait avant de pousser vos changements
- vous êtes sur une branche qui part d'une branche sur laquelle a été poussé des nouveaux commits, dans ce cas vous voulez vous mettre à jour non pas par rapport à la version partagée de votre branche courante mais par rapport à la branche d'origine
Dans les deux cas, on ne va pas créer de commit supplémentaire, on va juste rejouer l'historique de vos commits qui ne sont pas présents sur la branche depuis laquelle on rebase. Je parle bien de rejouer l'historique, car l'idée est de partir du principe que la branche partagée est bien la référence (ou la source de vérité, ou l'état actuel du projet), et vous vous voulez venir modifier cette référence avec vos commits, et comme vous vous êtes basé sur une référence obsolète, git va tenter de voir si vos changements sont compatibles avec l'état actuel.
Si vos commits sont compatibles : aucun souci, le rebase se passe sans que vous ne fassiez rien du tout (c'est le gros des cas normalement). Si vos commits ne sont pas compatibles (imaginons que vous avec modifiée une ligne, mais que votre collègue ait supprimé cette ligne, git ne peut pas savoir quoi faire de la modification que vous voulez effectuer, c'est donc des changements incompatibles), là git va vous demander d'effectuer un "merge conflicts" (ou fusion des conflits) de sorte à vous laisser la possibilité de décider ce que vous souhaitez faire (garder votre code et jeter celui de vos collègues, jeter votre code et garder celui de vos collègues, ou mixer les deux). Dans les deux cas, git va recréer chacun de vos commits pour avoir des commits qui se basent sur la nouvelle référence.
Quelques réponses aux gens qui disent...
"Moi je n'utilise que merge et ça fonctionne très bien !"
Alors on peut théoriquement choisir de n'utiliser que du merge, mais c'est pour moi un mauvais choix, rien que vu comment fonctionne le merge, le rebase et le résultat qui sort de l'usage de ces commandes.
L'idée comme je disais c'est que sur votre branche vous pouvez modifier l'historique autant que vous voulez et autant que possible considérer que votre branche source détient l'état de référence du projet. Donc vous devriez théoriquement vous mettre à jour par rapport à cette branche de référence via des rebases et utiliser le merge uniquement pour fusionner votre branche sur la branche de référence.
Ce qu'il faut comprendre c'est que si vous n'avez jamais eu de problème jusque-là, ça risque de venir, car faire un merge de la branche de référence vers votre branche veut dire que vous demandez à modifier votre branche avec les modifications de la branche de référence, donc potentiellement effacer vos modifications au profit du choix d'un de vos collègues (et ça sans que git vous demande comment gérer, merge implique d'office que l'autre branche vient modifier la vôtre).
Dans le même temps, faire le merge dans les deux sens, ça veut dire que vous allez avoir un historique qui n'est pas linéaire du tout, et donc qui va devenir totalement incompréhensible.
"le merge s'est fait tout seul quand j'ai pull !"
Alors déjà vous avez toujours le choix avec git ! Par défaut en effet c'est sûrement un merge qui sera effectué, mais normalement git vous demande la première fois que vous faite un pull de lui indiquer la stratégie que vous souhaiter prendre (je vous recommande rebase évidemment 😇). De cette façon vous n'allez jamais avoir de merge automatique et garder un historique linéaire.
Si vous préférez tout gérer à la main, vous pouvez aussi ajouter l'option --rebase (ou -r) pour demander explicitement le rebase au moment du pull.
"Quand j'ai fini je merge direct, je ne fais pas de rebase"
En soi ça fonctionne très bien ce cas. Vous ne perdrez jamais de code ici, mais vous aurez sûrement très souvent un commit supplémentaire inutile et un historique non linéaire.
"Avec les rebases j'ai déjà perdu du code !"
Si vous avez perdu du code pendant un rebase c'est sûrement, que vous avez fait une erreur quelque part ou si vous n'êtes pas passé par la ligne de commande potentiellement votre outil a fait dans votre dos quelque chose qui a créé cette erreur (au hasard regardez le nombre de commande qu'utilise VSCode pour faire un simple commit).
Dans ce cas tant pis, vous avez eu une mauvaise expérience, le plus important c'est comprendre pourquoi et corriger.
"On est en trunk based donc la question ne se pose pas !"
On l'entend moins mais ça arrive quand même : trunk based ne veut pas dire que vous avez une seule branche quand vous faite du git.
Git fonctionne avec plusieurs branches quoi qu'il arrive. Si vous êtes en trunk based, vous avez à minima : votre copie de travail, la branche master/main/trunk locale, la branche master/main/trunk distante (sur github, gitlab, etc.). Et quand vous faite un pull sur master/main/trunk vous êtes forcément dans le cas d'un rebase ou d'un merge.
Pourquoi vouloir un historique linéaire ?
À mon avis (mais je sais que beaucoup de gens partage cet avis) : il est préférable d'avoir un historique linéaire. C'est plus simple de suivre les changements dans le code, c'est plus simple de naviguer dans l'historique, c'est plus naturel au quotidien.
Dites-vous toujours une chose quand vous utilisez un outil de gestion de version : le but est toujours de pouvoir rapidement retrouver ce qui a provoqué l'état actuel, comment on est arrivé à créer tel bug, pourquoi tel morceau de code avait été fait de tel façon, etc. Plus votre historique est linéaire, plus c'est simple de remonter dans ce dernier. Dès que vous faite un commit de merge, vous créer un commit avec deux parents, donc si vous remontez dans l'historique, vous arrivez à un moment où l'histoire se sépare en deux branches (potentiellement plus de deux en cas d'enchaînement de merge), donc vous devez analyser plusieurs branches pour comprendre le problème, alors qu'avec un historique linéaire vous ne vous posez pas de question de comment naviguer.
Sources :