

Lundi soir (le 14 juin 2021), j'ai eu la chance d'avoir un petit aperçu de ce qui est prévu dans le futur pour Java via une présentation de José Paumard (ancien Maître de conférence, 25 ans de carrière, depuis quelques mois chez Oracle en tant que de DevRel Java Platform Group) dans le cadre d'un événement interne SFEIR qu'on appelle les QuarterBack.
Petit point pub : une des raisons qui m'a fait choisir SFEIR est la grande force de la communauté que représente SFEIR, aussi bien les Sfeiriens qui sont pour beaucoup moteur et toujours prêt à partager quelques astuces, un retour d'expérience ou une découverte, que des Top Speaker externes comme José Paumard grâce aux relations de quelques Sfeiriens (ici Didier Girard, le directeur Engineering de Sfeir). On a régulièrement donc la possibilité d'avoir des présentations de ce genre, venant de Top Speaker (parfois des Sfeirien aussi) qui nous donne un aperçu du futur. Si vous voulez en savoir plus sur Sfeir, et pourquoi pas rejoindre notre communauté, n'hésitez pas à me contacter en privé, je serai ravi d'échanger avec vous sur le sujet, mais revenons au sujet de l'article : Java 😉
Un morceau d'ambre
Le Pattern Matching en Java s'inscrit dans le cadre du projet Amber (en référence aux Chroniques d'Amber de Roger Zelazny). Ce projet vise à ajouter des fonctionnalités orientées productivité dans le langage Java.
On retrouve dans ce projet bon nombre de fonctionnalité comme le var qui est arrivé en Java 10. Mais ici nous allons nous concentrer sur un ensemble de fonctionnalité qui vise à apporter sur le long terme un vrai Pattern Matching à Java.
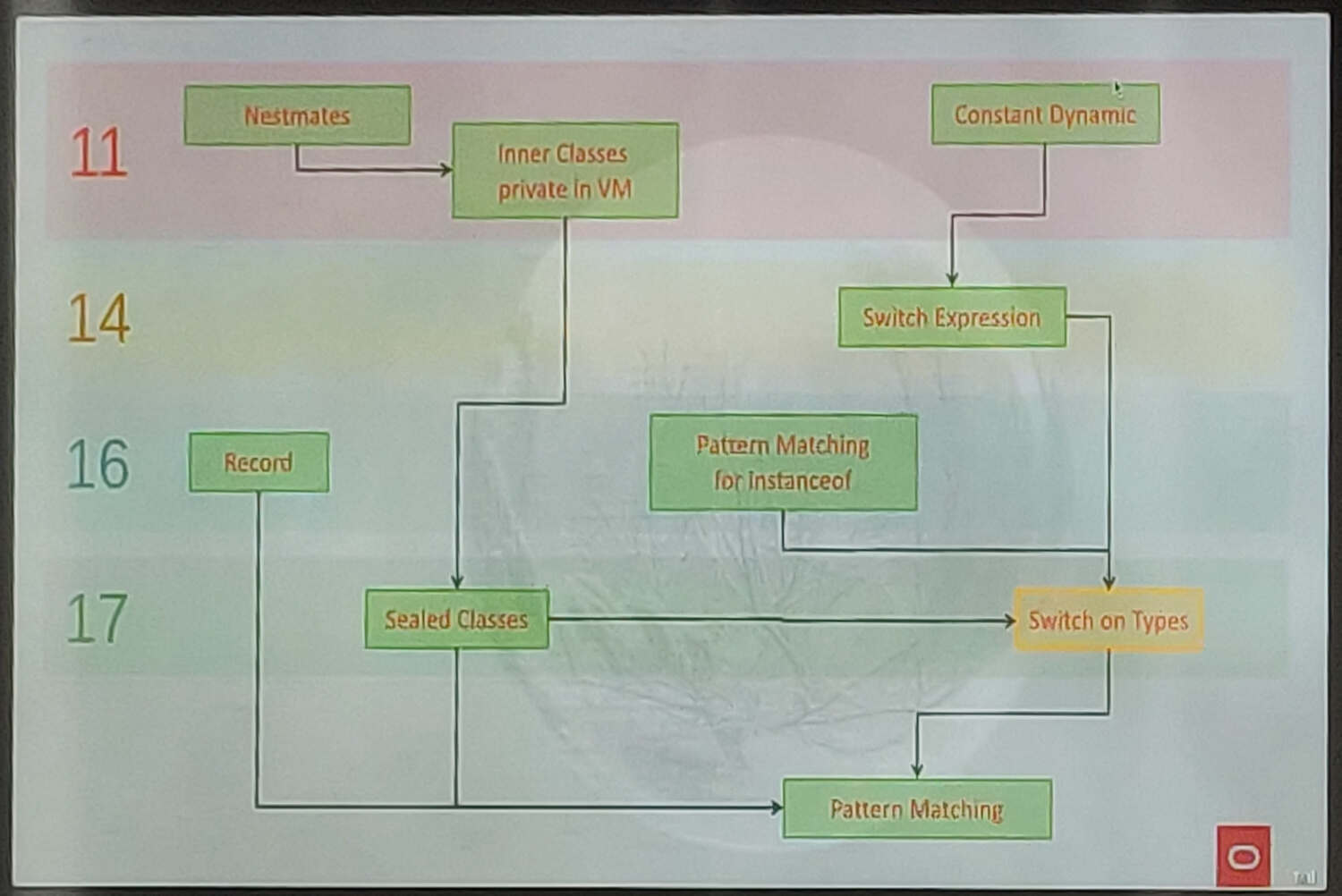
Les premiers ajouts qui préparent l'arrivée du Pattern Matching dans Java remonte à Java 7 selon José Paumard. Sur le planning de fonctionnalité dans ses diapos on part de Java 11 avec les Nestmates, Inner Classes private in VM et les Constant Dynamic, ici on est face à des changements dans la JVM. En java 14 est arrivé le switch expression, que j'aime beaucoup, car il offre une grande expressivité, avec la possibilité d'écrire des choses comme ça :
var area = switch(shape.getType()) {
case "Circle" -> Math.PI * shape.getWidth() * shape.getWidth();
case "Square" -> shape.getWidth() * shape.getWidth();
default: -1;
}
Pas besoin de poser de variable intermédiaire, on a une seule affectation avec une expression très claire qui est efficace une fois compilée.
Comme je l'avais évoqué dans mon billet sur Java 16, on retrouve l'arrivée des Record et du Pattern Matching via instanceof. Même si ce Pattern Matching est limité on peut déjà éviter pas mal de cas où on était obligé de caster, c'est maintenant au compilateur et à la JVM de faire ce travail pour nous. Les Record complètent bien ce Pattern Matching comme on peut facilement définir beaucoup de classes sans avoir la syntaxe très lourde d'un Java Bean.
En fin d'année sortira Java 17 et les sealed class ainsi qu'une preview sur le switch sur les types. Ce dernier apportera la possibilité d'appliquer le même Pattern Matching sur instanceof qu'on avait en Java 16 mais directement sur les switch avec une syntaxe plus légère et un bytecode plus efficace. On pourra écrire des choses comme ça :
var area = switch(shape) {
case Circle c -> Math.PI * c.getRadius() * c.getRadius();
case Square s -> s.getEdge() * s.getEdge();
default: -1;
}
Pour ceux qui ont déjà utilisé des langages comme OCaml ou Rust on retrouve très bien la syntaxe très expressive de ces familles de langage. On pourra donc exprimer très facilement certains traitements en gérant tous les cas possibles de notre hiérarchie. On pourra même éviter l'ajout d'un default si on est dans le cas d'une sealed class car le compilateur saura directement si on a géré tous les cas ou non, comme pour une enum.
Quelques mots sur les Records
Dans les grandes lignes les Record viennent apporter une touche de modernité aux traditionnels Java Bean mais avec une pointe d'immutabilité en plus. Mais les Record ne sont pas juste un sucre syntaxique, ils sont compilés très différemment d'une classe traditionnelle car la plupart des méthodes ont un Invoke Dynamic comme implémentation, c'est donc la JVM qui fourni le code qui sera exécuté quand on manipule les Record pour avoir des performances amélioré en fonction de la plateforme.
D'un point de vue plus architectural/conceptuel, José défini un Record comme une classe définie exclusivement à partir de composants, ces composants se sont les propriétés que va posséder ce Record. À partir de la simple liste des propriétés d'un record, le compilateur va produire des accesseurs (on ne parle pas de getter, car ils n'ont pas la forme getX() mais uniquement x()), des méthodes courantes comme equals(), hashcode() et toString() ainsi qu'un constructeur canonique (qui permet de construire une instance du record en passant en paramètre la valeur de chaque propriété).
Il y a quelques contraintes : un record est immutable (c'est à la fois un avantage et une contrainte), un record est final (on ne peut donc pas l'étendre) et un record ne peut étendre une classe (mais peut par contre très bien implémenter des interfaces). Toutes ces contraintes sont là à dessein et permettre de garantir une certaine sécurité dès la compilation.
J'ajoute une note sur le fait que les Record sont différents dans l'approche technique des data class de Kotlin et des annotations Lombok. Pour commencer ce dernier ne va faire qu'ajouter du code à la compilation pour ajouter les méthodes qu'on écrit pas via les annotations qu'on ajoute sur une classe. Les data class de Kotlin ont une approche similaire aux annotations de Lombok mais c'est un compilateur dédié qui traite ça. Dans les deux cas si on décompile le .class qui est généré on trouvera plus ou moins la même chose que si on avait écrit un simple Java Bean avec éventuellement quelques méthodes en plus. Comme dit plus haut les Record ont vraiment une existence particulière dans la JVM. José propose de lire cet article qui détaille très bien la différence entre Record, data class de Kotlin et Lombok annotation : https://nipafx.dev/java-record-semantics/
Et les sealed class ?
J'avoue qu'avant lundi, je n'avais pas très bien compris l'intérêt des sealed class. Sceller une classe n'a que peu d'intérêt en soit, par contre si on couple avec sealed class et Pattern Matching on obtient quelque chose de très puissant.
En effet sceller une hiérarchie de classe permet d'imposer une liste de class restreinte qui vont constituer une hiérarchie. Ça implique deux choses : on ne peut pas étendre cette liste dynamiquement, à la compilation le compilateur connait exactement l'ensemble de toutes les classes d'une hiérarchie. De facto on peut utiliser une hiérarchie de sealed class pour faire du Pattern Matching via switch sans branche default (aussi appelé "total switch") de sorte à être optimale et avoir un filet de sécurité dès la compilation sur le fait qu'on oublie aucun cas.
Et dans le futur ça donnera quoi ?
José nous a montré pas mal de portion de code qui seront fonctionnels si le cap est maintenu dans le futur, sans forcément qu'une version de Java soit clairement définie comme cible d'implémentation.
La principale amélioration qui va venir compléter le Pattern Matching c'est la possibilité de faire de la destructuration via la validation d'un pattern. Partons d'un exemple :
if (o instanceof Rectangle(int width, int height)) {
// do something with width and height
}
Dans cet exemple on voit qu'on peut directement extraire les propriétés d'une instance de Rectangle dès la validation du type via le Pattern Matching via instanceof. C'est une mécanique assez puissante en termes d'expressivité, mais on peut aller encore plus loin avec un switch :
abstract sealed class Shape permits Square, Circle {}
record Square(int edge) implements Shape {}
record Circle(int radius) implements Shape {}
...
double area = switch(shape) {
case Square(int edge) -> edge*edge;
case Circle(int radius) -> Math.PI*radius*radius;
}
Ici on peut directement extraire les propriétés d'une instance de manière très expressive.
Les équipes qui développent Java envisage même l'ajout du mot clé match qui permettrait de ne valider qu'une seule branche de pattern et exclure toutes les autres ce qui donnerait par exemple :
match Circle(var radius) = shape
else throw IllegalStateException("Not a Circle");
// do something with radius
Ici on comprend bien qu'on pourra très facilement s'assurer d'avoir reçu le type attendu pour les cas où on en a besoin, on évitera ainsi des cast hasardeux.
Il est aussi prévu qu'on puisse ignorer une propriété qu'on ne souhaitera pas utiliser via un underscore comme ceci :
double area = switch(shape) {
case Square(int edge) -> edge*edge;
// case Circle(int radius, Point center) -> Math.PI*radius*radius;
case Circle(int radius, _) -> Math.PI*radius*radius;
}
Conclusion
Ce meetup avec José Paumard aura été riche en découverte et en discussion. J'ai pu re-découvrir les Record, les sealed class et le Pattern Matching ainsi que pas mal de nouveauté à venir dans Java.
Je ne peux que vous conseiller de creuser le sujet dès que vous aurez un peu de temps 😁
Crédit photo : https://pixabay.com/photos/hand-keep-puzzle-finger-match-523231/