

Cet article est la transcription d'un talk ("Java à la vitesse de la lumière grâce au Graal !") que j'ai donné au JUG Summer Camp de La Rochelle (replay ici : https://youtu.be/XFJ4-yNdTbs) et que je vais re-donner prochainement à Nantes, suivez-moi sur les réseaux si ça vous intéresse 😎
Reprenons les bases
On oppose très souvent les langages interprétés et les langages compilés.
D'un côté on va trouver les langages interprétés avec par exemple PHP, JavaScript, Lua, Python et pleins d'autres. L'idée c'est qu'on ne va pas créer de binaire, le code qu'on écrit sera lu par un programme qui va interpréter le code source directement, ce qui permet généralement d'avoir un code qui est portable entre différentes plateformes.
De l'autre côté on trouve les langages compilés comme C, C++, Ada, et beaucoup d'autres. Là on va créer un binaire pour exécuter le programme, le binaire est composé d'instruction machine et est donc lié à une plateforme particulière. Si on veut porter notre code sur plusieurs machines il faudra donc recompiler pour chaque cible. Cet inconvénient à tout de même un avantage : l'exécution, en particulier le temps de démarrage, est beaucoup plus rapide.
Et Java dans tout ça ? Java est un peu à mi-chemin entre les deux mondes. On compile nos fichiers .java en .class, qu'on va agréger dans un .jar, mais un .class ne contient pas de code machine, il s'agit de bytecode, qui est un langage bas niveau proche d'un assembleur qui sera interprété par la suite, et un jar c'est ni plus ni moins qu'un zip contenant les .class et une structure de dossiers/fichiers respectant des conventions.
Et la JVM dans tout ça ? La Java Virtual Machine, c'est un conteneur qui va servir à interpréter le bytecode et qui va faire un peu de "magie" pour nous simplifier la vie : compiler en mode JIT (Just In Time) le bytecode en code machine si besoin, faire abstraction de l'OS et fournir des méthodes d’interaction avec ce dernier, un garbage collector pour ne pas s'occuper de la mémoire, une gestion des Threads, etc. En fait la JVM c'est la brique qui fait qu'on peut quasiment ne jamais s'occuper de comment fonctionne l'OS et la machine qui va exécuter notre programme.
Et donc GraalVM, qu'est-ce que c'est ?
Après tout ces rappels qui sont assez importants pour la suite, on va parler du cœur du sujet : GraalVM. Pour faire simple : c'est un ensemble d'outil qui vient se greffer autour de l'OpenJDK. Le but n'est pas de remplacer l'OpenJDK, ni de le réécrire, juste de proposer une nouvelle approche pour le livrable de production avec principalement deux grandes nouveautés : la compilation native et une JVM polyglotte.
Vous avez dit polyglotte ?
Habituellement une JVM va uniquement comprendre le bytecode, une JVM polyglotte va comprendre plusieurs langages. En fait, quand on utilise GraalVM, on va avoir la possibilité d'exécuter du code JavaScript (dont Node.js), Ruby, Python, R, LLVM et WebAssembly (expérimental pour ce dernier) directement sur la JVM dans le même AST (Abstract Syntax Tree) que le bytecode, donc théoriquement sans aucune latence. On aura juste une API dans chaque langage permettant de faire le pont entre les langages (par exemple demander l'exécution de code JavaScript depuis du Java).
Ici je vous donne deux exemples de code qu'on peut écrire grâce à l'aspect polyglotte de la JVM de GraalVM.
import org.graalvm.polyglot.*;
class Polyglot {
public static void main(String[] args) {
Context polyglot = Context.create();
Value array = polyglot.eval("js", "[1,2,42,4]");
int result = array.getArrayElement(2).asInt();
System.out.println(result);
}
}
Ce premier exemple est tiré de la documentation de GraalVM. On y voit comment créer un contexte d'exécution permettant d'évaluer du code JS créant un tableau et ensuite comment le manipuler en Java.
import org.graalvm.polyglot.*;
public class App {
public static void main(String[] args) {
try (Context context = Context.create()) {
var x = 1;
context.eval("js", "const y=2");
Value fn = context.eval("js", "function foo(x) { return x+y; } foo"});
System.out.println(fn.execute(x)); // will print 3
}
}
}
Ici un exemple de mon cru qui montre comment on peut appeler une fonction crée en JS depuis Java en exploitant une variable globale du contexte JS et un paramètre qu'on passera depuis Java au moment de l'appel.
Pourquoi compiler en natif ?
Le premier point, c'est que sur une JVM classique on va avoir un temps de démarrage relativement long (assez souvent plusieurs secondes voir dizaines de secondes). Ce n'est pas forcément un problème mais dans certains cas d'usage où le temps de démarrage peut être un problème comme sur le cloud où on peut démarrer/couper des services assez souvent, ça peut être gênant. On peut aussi se dire qu'un JRE (Java Runtime Environment) c'est assez lourd (OpenJDK c'est à minima une bonne centaine de Mo à monter en RAM, et plusieurs centaines de Mo à distribuer) alors qu'on n'utilisera qu'un fragment du JRE. Plus on a de code à charger, plus le démarrage est long, et plus le JIT a de travail.
En face, avec GraalVM on va changer de raisonnement. Plutôt que d'embarquer systématiquement tous les jar, après la compilation du jar on va faire une passe de compilation native : on va compiler en code machine le bytecode de l'ensemble de notre application ainsi que les librairies dont on dépend et les parties du JRE qu'on utilise pour faire un binaire prêt à être exécuté sans passage par un interpréteur ou un JIT. On aura plus de jar, plus de JVM/JDK à installer, mais un binaire all-in-one, avec tout ce qui est nécessaire, y compris une JVM plus adapté à la situation (typiquement on aura plus de JIT).
Évidemment, il n'y a pas que des avantages à compiler en natif, et je pense que c'est important de le noter. Qui dit exécutable all-in-one veut aussi dire qu'on ne peut plus charger dynamiquement de jar. On n'aura plus accès à toute l'API Reflexion, en fait pour être plus optimisé et parce qu'une fois compiler en natif certaines options sont compliqués à gérer on ne peut plus tout faire à l'exécution, et une partie sera même calculé à la compilation. Comme le binaire cible une plateforme, il faudra recompiler pour chaque plateforme. Et pour moi le plus gros point noir aujourd'hui c'est qu'on ne suit plus les versions standard de Java, au moment où j'écris l'article Java 16 est en mode expérimental, on trouvera Java 8 et Java 11 comme versions stables supportées.
Quelques métriques
Après un peu de théorie, je vous propose de rentrer un peu dans la pratique avec quelques métriques.
Selon l'équipe GraalVM
L'équipe GraalVM fourni quelques métriques, mais pas vraiment à jour.
Je vous met le lien dans les sources en fin d'article, mais ils comparent GraalVM 19 en mode HotSpot (quasiment équivalent à OpenJDK 11 classiques) et le mode natif de la même version de GraalVM.
Ils annoncent principalement un temps de démarrage en moyenne 50 fois plus rapide et une consommation 5 fois plus faible en se basant sur des applications écrites avec des frameworks "cloud native" (donc globalement pensé de base pour être optimisé avec GraalVM).
De mon côté
Vous vous en doutez, j'ai moi-même fait quelques mesures. Je me suis intéressé surtout au temps de compilation, la taille du livrable, la consommation RAM et la vitesse de démarrage. Pour chaque mesure (sauf la taille du livrable) j'ai effectué l'action 3 fois pour chaque mode pour faire une moyenne et ne pas dépendre d'un défaut d'ordonnanceur sur ma machine.
Tous mes tests ont étés effectué sous ArchLinux avec un Kernel 5.12.15-arch1-1, avec un CPU Intel Core i7 8700K (6 cœurs / 12 threads) et 24Go de RAM (2x8Go en dual channel + 8Go seuls).
Côté compilation j'ai comparé ces trois options :
- OpenJDK 11.0.12 : tout ce qu'il y a de plus standard
- GraalVM CE 21.2.0 en mode HotSpot : compilation identique à l'OpenJDK mais avec le SDK GraalVM, on ne passe pas en natif, on s'arrête au jar
- GraalVM CE 21.2.0 en mode natif : compilation d'un binaire all-in-one
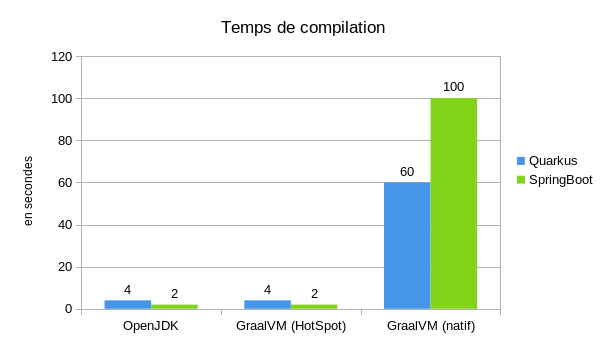
On voit que passer sur une compilation native va demander du temps, on passe d'un temps de compilation de l'ordre de la seconde à une compilation native de l'ordre de la minute.
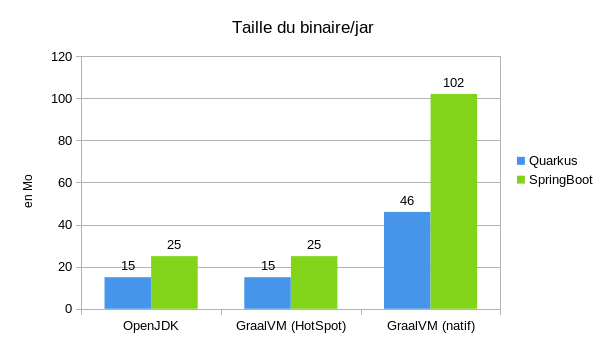
Comme on passe sur un binaire all-in-one, le binaire est forcément plus gros (environ 5 fois plus) quand on compare aux jar (pour Quarkus le jar de notre code et les librairies, pour SpringBoot l'uberjar), mais il faut ajouter 325Mo pour l'OpenJDK et 967Mo pour le JDK GraalVM si on voulait distribuer notre application.
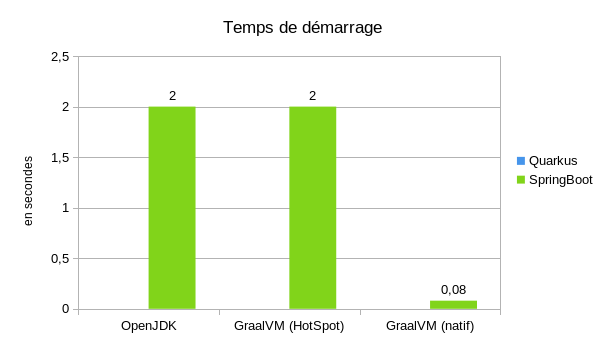
Pour le temps de démarrage, je me suis contenté de la mesure fournie par SpringBoot (Quarkus ne fournit par directement cette information). On voit qu'on réduit fortement le temps de démarrage en passant en natif. Le temps de démarrage est environ 20 fois plus court.
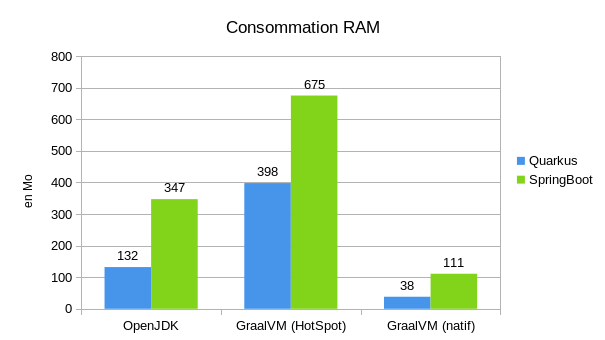
Du côté de la consommation de RAM on voit aussi un gros gain, entre l'OpenJDK et GraalVM natif (environ 3 fois moins de RAM consommé). Par contre là où sur tous les autres point, GraalVM en mode classique était équivalent à l'OpenJDK, là on voit que la consommation RAM est beaucoup plus importante (environ 2 à 3 fois plus grande).
Prêt pour la production ?
Sans forcément trop de détail, on sait que de grands acteurs comme Oracle (forcément c'est eux qui développent GraalVM), Twitter, Facebook utilisent du GraalVM. Au minimum sur certaines parties de leurs applications. On sait aussi que ce n'est pas que pour des POC dans un coin, Twitter avait annoncé que chaque tweet passait forcément par du code compilé avec GraalVM.
On peut aussi voir des frameworks comme Micronaut ou Quarkus qui émergent en se basant sur les capacités de GraalVM. Tout est pensé pour suivre au maximum la logique de GraalVM (sans pour autant se couper de la possibilité de fonctionner sur un OpenJDK).
Côté Spring, on voit que la communauté commence à vraiment s'y intéresser. Un module a été créé justement pour profiter facilement de GraalVM en natif avec SpringBoot : Spring Native. C'est ce module que j'ai utilisé pour mes tests, c'est super simple et super efficace. Par contre je ne pense pas que l'intégralité des modules SpringBoot soient compatibles aujourd'hui, il faut voir au cas par cas, mais je pense qu'à l'avenir tout ou presque sera compatible !
Conclusion
Du coup on y va ou pas ? À mon avis, sans foncer bêtement tête baissé dans l'utilisation de GraalVM il faut se poser la question.
Déjà est-ce que ça peut nous apporter un gain. GraalVM va permettre de gagner en mémoire et CPU (et donc potentiellement faire plus de traitement sans changer de machine (virtuelle)), gagner en temps de démarrage, gagner sur la taille des livrables. Donc ça ne va pas résoudre tous vos problèmes magiquement, mais ça peut vous aider !
Sources :
- https://www.graalvm.org/
- https://www.graalvm.org/reference-manual/polyglot-programming/#start-language-java
- https://www.graalvm.org/reference-manual/wasm/
- https://medium.com/graalvm/lightweight-cloud-native-java-applications-35d56bc45673
- https://www.oracle.com/fr/a/ocom/docs/graalvm-twitter-casestudy-constellation.pdf
- https://medium.com/graalvm/graalvm-at-facebook-af09338ac519
Crédit photo : https://pixabay.com/photos/king-coast-arthur-tintagel-statue-3879305/