

J'adore lire. C'est super important dans ma vie. Les 2000 livres qui vivent dans mon bureau en sont une bonne démonstration. Parce que oui : je préfère encore et toujours le format papier !
Mais parfois, le numérique c'est plus pratique... ou parfois la seule option ! Et parfois faut ruser un peu...
Contexte
Si c'est que la partie technique qui vous intéresse, je vous conseille de sauter cette partie. 😉
Mon cas : j'ai découvert (avec 3 ans de retard…) qu'il sortait au Japon une nouvelle série manga Yu-Gi-Oh! ("petite" passion depuis l'enfance 🤓). Si je précise "au Japon" c'est que vous vous en doutez : y'a pas de traduction officielle… Même en anglais… Japonais uniquement…
Donc en gros, j'ai quoi comme option :
- j'achète les volumes en japonais en import, ça va me coûter super cher, je ne pourrais pas les lire…
- j'achète les volumes en ebook japonais (je pense que ça doit se trouver), ça va pas me coûter trop cher, mais je vais sûrement devoir bidouiller pour mettre ça sur ma Kindle et ce sera toujours en japonais, donc je pourrais toujours pas le lire…
- je lis des scantrads sur l'ordi, mais je me connais je lirais jamais jusqu'au bout, je serai pas confortable… (surtout si c'est en lecture en ligne avec un chargement entre chaque page…)
- je trouve une solution pour passer des scantrads en ligne à ma Kindle et je pourrais lire ça tranquillement…
Évidemment j'ai choisi la dernière option : j'ai une Kindle Scribe pour 2 raisons, la prise de note et la lecture (en particulier de manga), pouvoir lire en étant confortable ça fait partie intégrante du plaisir de la lecture pour moi !
Note : je ne vous recommanderais pas forcément la Kindle Scribe. Ce n'est pas une mauvaise tablette de lecture, elle me convient à moi, mais ce n'est clairement pas la seule option. Quelques éléments :
- si vous ne lisez pas de comics/manga/BD : ne prenez pas une tablette 10", une 6" c'est largement mieux (j'ai eu une Kindle Paperwhite non rétro-éclairée pendant des années), c'est beaucoup plus léger et ça prend vraiment pas de place pour voyager avec ;
- si votre priorité c'est la prise de note : il y a des options plus pointues que la Kindle Scribe, la référence c'est la ReMarkable, mais la Onyx Boox Notes est à priori largement à la hauteur ;
- si votre priorité c'est la lecture de comics/manga/BD : la Onyx Boox Notes ou Kobo Elipsa sont des meilleurs choix ;
La Kindle Scribe est un bon appareil, très diffusé donc avec aussi plus facilement des pièces de rechange si besoin de réparer, mais pas la seule option, surtout avec toutes les limitations dans les formats supportés. Donc si vous n'avez pas choisi un matériel, n'hésitez pas à mettre le nez chez la concurrence avant d'arrêter votre choix !
Je ne vous donnerai pas de lien pour éviter de me faire déréférencer, mais c'est très facile de trouver des scantrads en ligne, donc je vous fais confiance pour trouver !
Récupérer le contenu
La première étape c'est récupérer le contenu.
Plusieurs options :
- trouver un lien de téléchargement ? Dans mon cas c'était 100% en lecture en ligne…
- parcourir toutes les pages une par une et enregistrer les images au fur et à mesure que je défile les pages ? Long, fastidieux, et pas du tout motivant, mais c'était une option envisageable… ;
- faire un script qui attaque l'API du site pour récupérer la liste des images pour tout récupérer proprement rangé chapitre par chapitre ? Ça ça me va ! 😎
Ça ressemble à quoi ? Tout simplement : j'ouvre la page de la fiche de la série, j'ouvre les outils de développeurs, je filtre sur XHR pour ne voir que les appels API (et exclure les images, .js, etc.), et :
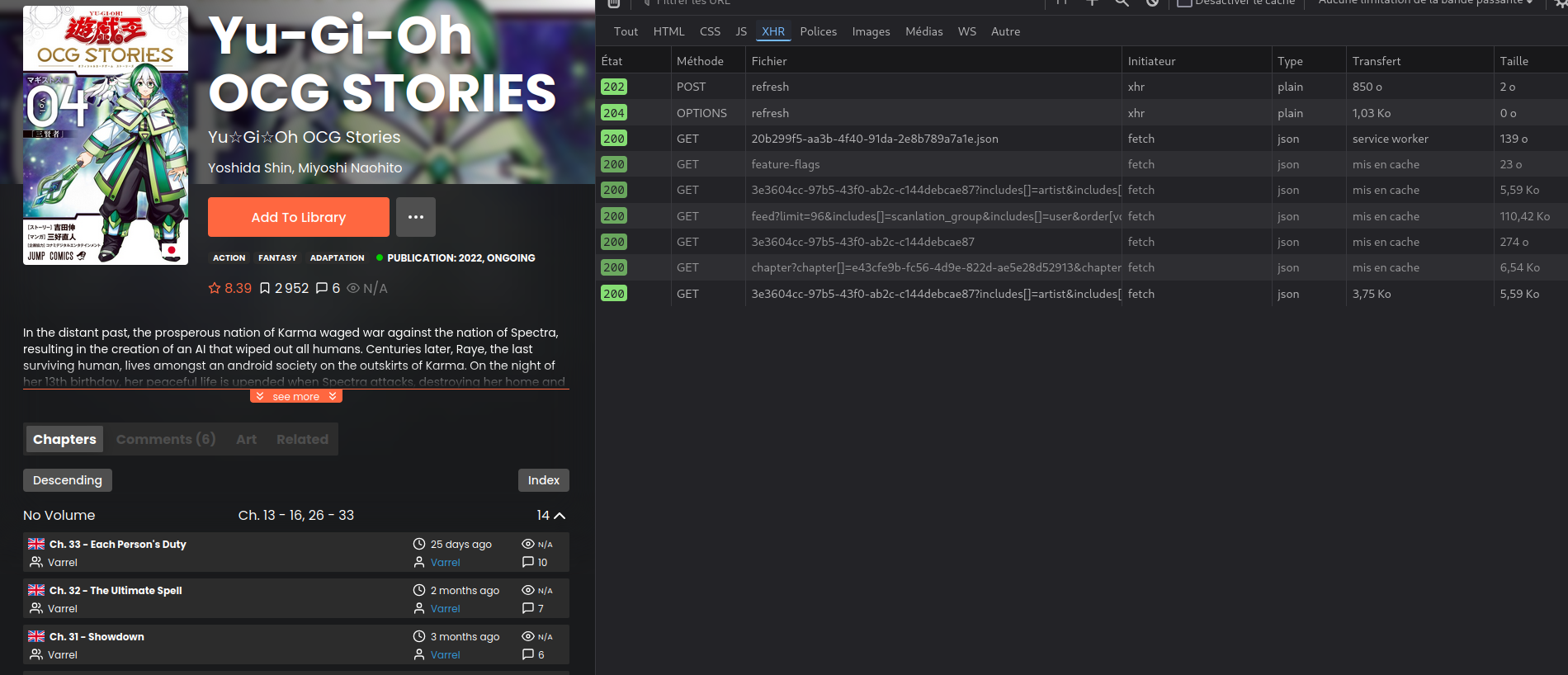
Ça marche ! 🤓
On le voit sur la capture, mais on voit bien une succession d'appel qui renvoie des JSON ! Je vous passe mon inspection des requêtes en passant de page en page, mais j'arrive à ça :
- un endpoint qui permet de récupérer la liste des volumes et dans chaque volume les chapitres : https://api.example.com/manga/3e3604cc-97b5-43f0-ab2c-c144debcae87/aggregate?translatedLanguage[]=en&groups[]=28c28c4c-f656-46ad-993d-c9de461e2f3e
- un endpoint pour récupérer les différentes pages d'un chapitre : https://api.example.com/at-home/server/${chapterId}?forcePort443=false
- l'url qui permet de télécharger une image directement : ${baseUrl}/data/${hash}/${name} (baseUrl étant renvoyé dans le endpoint du chapitre)
En soi rien de bien compliqué pour la suite : j'ai fait un script avec Deno (je vous ai déjà dit que j'aimais Deno et que c'était bien ? 🙈) qui commence par récupérer la liste des chapitres, puis pour chaque chapitre une requête pour récupérer la liste des pages, puis pour chaque page un appel pour télécharger l'image.
Facile non ?
Oui mais pas tout à fait. Déjà il faut prendre en compte qu'il y a une trentaine de chapitres d'une trentaine de pages (grosse maille : 1 + 30 + 30x30 = 931 appels et 900 images à télécharger), donc ça va prendre pas mal de temps à télécharger en séquence… Sauf qu'on est pas obligé de faire ça en séquence ! Je suis avec Deno en TypeScript, donc je peux laisser Deno gérer le pool de connexion pour télécharger en vitesse maximum !
Comment je fais ça ?
const volumes = await getVolumes();
const pagesQueue: Promise<unknown>[] = [];
const rootDir = "scans";
Deno.mkdirSync(rootDir);
for (const volume of Object.values(volumes.volumes)) {
const volumeDir = `Tome ${volume.volume}`;
Deno.mkdirSync(`${rootDir}/${volumeDir}`);
for (const chapter of Object.values(volume.chapters)) {
const chapterDir = `Chapitre ${chapter.chapter}`;
Deno.mkdirSync(`${rootDir}/${volumeDir}/${chapterDir}`);
const pages = await getChapterPages(chapter.id);
for (const page of pages.chapter.data) {
const path = `${rootDir}/${volumeDir}/${chapterDir}/${page}`;
const imageUrl = getImageUrl(pages.baseUrl, pages.chapter.hash, page);
pagesQueue.push(
getImage(imageUrl)
.then((img) => Deno.writeFile(path, img))
.then(() => console.log(`${path} %cOK`, "background-color: green"))
.catch(() =>
console.log(`${path} %cKO (${imageUrl})`, "background-color: red")
)
);
}
}
}
await Promise.all(pagesQueue);
Le code est un peu velu, mais dans les grandes lignes l'idée d'enchaîner tous les appels d'images et mettre la promesse qui est retournée par l'appel à fetch() (qui est caché dans l'appel à getImage()) dans une liste de Promise (que j'ai appelé pageQueue ici) et une fois qu'on a construit tous les appels, là je demande à attendre la résolution de l'ensemble des Promise. Je sais comment fonctionne un moteur JavaScript, il crée un pool de connexion par domaine automatiquement, donc mettre tous les appels en block comme ça va juste maximiser le pool de connexion avec une rotation automatique à la fin de chaque appel sans que je n'aie rien eu à lui dire.
Là il suffit de lancer et attendre ! Et c'est un peu long on va pas se mentir… mais c'est pas comme si j'avais besoin de performance ou que j'allais faire ça tous les jours donc c'est pas bien grave 😇
Note 1 : si vous devez refaire quelque chose du genre, je vous conseille de travailler sur la gestion des erreurs, ici j'ai fait le minimum, à savoir afficher OK/KO pour gérer la main les quelques erreurs mais pas plus. On peut clairement faire mieux !
Note 2 : vous noterez que les appels à
console.log()contienne du style, les OK sont affichés avec un fond vert, les KO avec un fond rouge. C'est une fonctionnalité native en Deno.
À cette étape on a un ensemble de dossier avec des images, de ce style :
scans
├── Tome 1
│ ├── Chapitre 1
│ │ ├── 10-5b128297914ae59a96bc2f1bfae904f1c05fdb8465423ea1f3d2700f11c37304.png
│ │ ├── 1-0aa48b58eaa8a97a51cbfcf7209cf7d7e0469fc009239a5bf3b67c2ded45ed41.jpg
│ │ ├── 11-c24806cc377a2a1c75439487035d48c58e686a72622e48f5319a1024c5bcb65b.png
│ │ ├── 12-4e2484ca6a5d7813b72e114d147a95c9aedc3318ec938dd7bf45e56875f49863.png
│ │ ├── ...
│ │ └── 9-00c51d667b7100d9a4bb3d9df9db55aebe6034c271d981c910eb1ea63b4c5fee.png
│ ├── Chapitre 2
│ │ ├── 1-01a1b8bee2574097349f4a4b902617ed9f07c59e8609f2894c7232b43eac4de7.png
│ │ ├── 10-1b75501840e28d6065e4a2700153207e20f49bfb0a5eb175c12523bc426c4810.png
│ │ ├── 11-87486e7b190f498682d5979b352adcf928c74a093509bfc1f043948585a29cc8.png
│ │ ├── ...
Maintenant on en fait quoi ?
Les formats adaptés aux bandes dessinées
Le format le plus basique ce serait de ne rien faire de plus. En effet pour lire sur un ordinateur, c'est suffisant, on peut ouvrir le dossier d'un chapitre et naviguer dans les images. Mais ce n'est pas ce que je veux.
J'ai fait une petite recherche sur les formats courants qui existent pour des bandes dessinées :
- CBZ (ou CBR / CB7 / CBA / CBT)
- EPUB
- MOBI
Et c'est à peu près tout, ou bien c'est format un peu trop limité en termes de lecteur pour les ouvrir ensuite…
Le format EPUB c'est plutôt non… Un EPUB c'est un fichier qui défini du contenu mais peu comment il doit être affiché. Oui on peut afficher des images dans un EPUB, mais ce n'est pas très adapté. De plus ce format n'est pas supporté par ma Kindle Scribe, donc ce serait pas mal de travail pour devoir ensuite refaire une conversion…
Le format MOBI, c'est supporté par les Kindle mais c'est plutôt pensé pour du contenu texte… À noter aussi que c'est un format assez ancien, propriétaire et qui n'est pas très simple à créer manuellement.
Un PDF, c'est pas mal au sens où je peux en faire des parfaitement adaptés au format de la Kindle, c'est directement lu par la Kindle, mais ce serait long d'en faire directement…
CBZ du coup ? C'est un format très pauvre (je vous explique plus loin), mais c'est simple à fabriquer, c'est facile de le passer dans des convertisseurs (y compris par mon gestionnaire de ebook préféré : Calibre).
Créer des CBZ
Un fichier CBZ c'est quoi ? C'est simple : un zip contenant des images à plat, qu'on renomme en .cbz. Fini.
CBZ c'est un acronyme pour Comic Book Zip. On trouve aussi des CBR (Comic Book Rar), CB7 (Comic Book 7z), CBT (Comic Book Tar) ou CBA (Comic Book Ace). Globalement dites-vous que chacun a ses préférences sur le format d'archive mais l'idée est toujours la même : une archive qui contient des fichiers images à plat, sans possibilité de sous dossier, l'ordre alphabétique des fichiers donne l'ordre des pages, pas vraiment de métadonnées complètement standard (mais on peut faire des choses).
Donc si je résume : pour transformer en volume relié mes fichiers images, je peux simplement tout zip et renommer .cbz, faut juste que je fasse attention à ce que tout soit dans l'ordre alphabétique.
Si je regroupe par chapitre ça ira super vite mais ce sera pas très pratique à lire, si je regroupe en volume je n'aurais pas moyen de mettre de sommaire pour naviguer dans les chapitres. De mon côté je préfère l'option 2 : avoir les volumes reliés.
Comment je fais ça pour aller vite ?
Pour organiser les fichiers pour faire des .cbz :
Deno.mkdirSync(TIDY_SCANS_DIR);
const volumeDirs = Deno.readDirSync(DL_SCANS_DIR);
for (const volumeDir of volumeDirs) {
const volumeNumber = volumeDir.name.split(" ")[1];
const volumePart = leftPad(volumeNumber, NUMBER_PAD);
const tidyVolumeDir = `./${TIDY_SCANS_DIR}/Tome ${volumePart}`;
const dlVolumeDir = `./${DL_SCANS_DIR}/${volumeDir.name}`;
Deno.mkdirSync(tidyVolumeDir);
const chapterDirs = Deno.readDirSync(dlVolumeDir);
if (volumeNumber !== "none") {
Deno.copyFileSync(`${dlVolumeDir}/${COVER_NAME}`, `${tidyVolumeDir}/000_000${COVER_EXT}`);
}
for (const chapterDir of chapterDirs) {
if (!chapterDir.isDirectory) {
continue;
}
const chapterNumber = chapterDir.name.split(" ")[1];
const chapterPart = leftPad(chapterNumber, NUMBER_PAD);
const dlChapterDir = `${dlVolumeDir}/${chapterDir.name}`;
const pages = Deno.readDirSync(dlChapterDir);
for (const page of pages) {
const pageNumber = page.name.split("-")[0];
const pagePart = leftPad(pageNumber, NUMBER_PAD);
const pageExt = page.name.split(".").pop();
const tidyPageName = `${tidyVolumeDir}/${chapterPart}_${pagePart}.${pageExt}`;
Deno.copyFileSync(`${dlChapterDir}/${page.name}`, tidyPageName);
}
}
}
L'idée c'est globalement la même chose que le script de téléchargement : je parcours les dossiers puis je copie dans un autre dossier sans découper en chapitre mais en nommant correctement les fichiers pour que tout reste dans l'ordre. Par exemple scans-tidy/Tome 004/021_028.png pour la page 28, du chapitre 21, qui est présent dans le tome 4.
Pour zip et faire des fichiers .cbz à partir du dossier scans-tidy :
for folder in *; do 7z a "./$folder.cbz" "./$folder/*";done
Ajouter des métadonnées
Côté métadonnées c'est compliqué mais on a quand même des options avec le format CBZ.
De ce que j'ai compris le format le plus pris en compte (pas standard, c'est juste qu'il s'est beaucoup diffusé donc il a un support plutôt répandu), c'est le Comicinfo.xml, avec deux options pour l'ajouter à notre CBZ : soit sous forme de commentaire sur l'archive (je découvre au passage qu'on peut faire ça), soit sous la forme d'un fichier Comicinfo.xml dans l'archive (toujours à la racine, un CBZ c'est une archive sans hiérarchie possible).
J'opte pour la version fichier. Et j'en fabrique un avec Calibre avec l'aide de l'extension Embed Comic Metadata (pas de site officiel, on retrouve l'extension sur Github, mais il n'y a pas de bricolage à faire pour que ça fonctionne, elle est disponible via le menu plugins de Calibre directement) histoire de pas trop me casser la tête à tâtonner sur la découverte du format pour avoir quelque chose de correctement lu par Calibre. En remplissant au maximum les infos, puis en générant le fichier j'ai ça :
<?xml version="1.0"?>
<ComicInfo xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Title>Yu-Gi-Oh! OCG Stories Tome 01</Title>
<Series>Yu-Gi-Oh! OCG Stories</Series>
<Number>1.0</Number>
<Year>2022</Year>
<Month>12</Month>
<Day>2</Day>
<Writer>Shin Yoshida</Writer>
<Publisher>V Jump</Publisher>
<Tags>Yu-Gi-Oh!</Tags>
<LanguageISO>en</LanguageISO>
</ComicInfo>
Facile à comprendre donc non ?
Du coup, je m'embête pas, j'en ajoute un par tome dans le dossier qui va bien et j'ajuste manuellement le contenu, car cinq fichiers ça ne vaut l'effort de l'automatiser à mon avis.
Du coup là je peux importer mes fichiers .cbz dans Calibre et retrouver mes métadonnées…
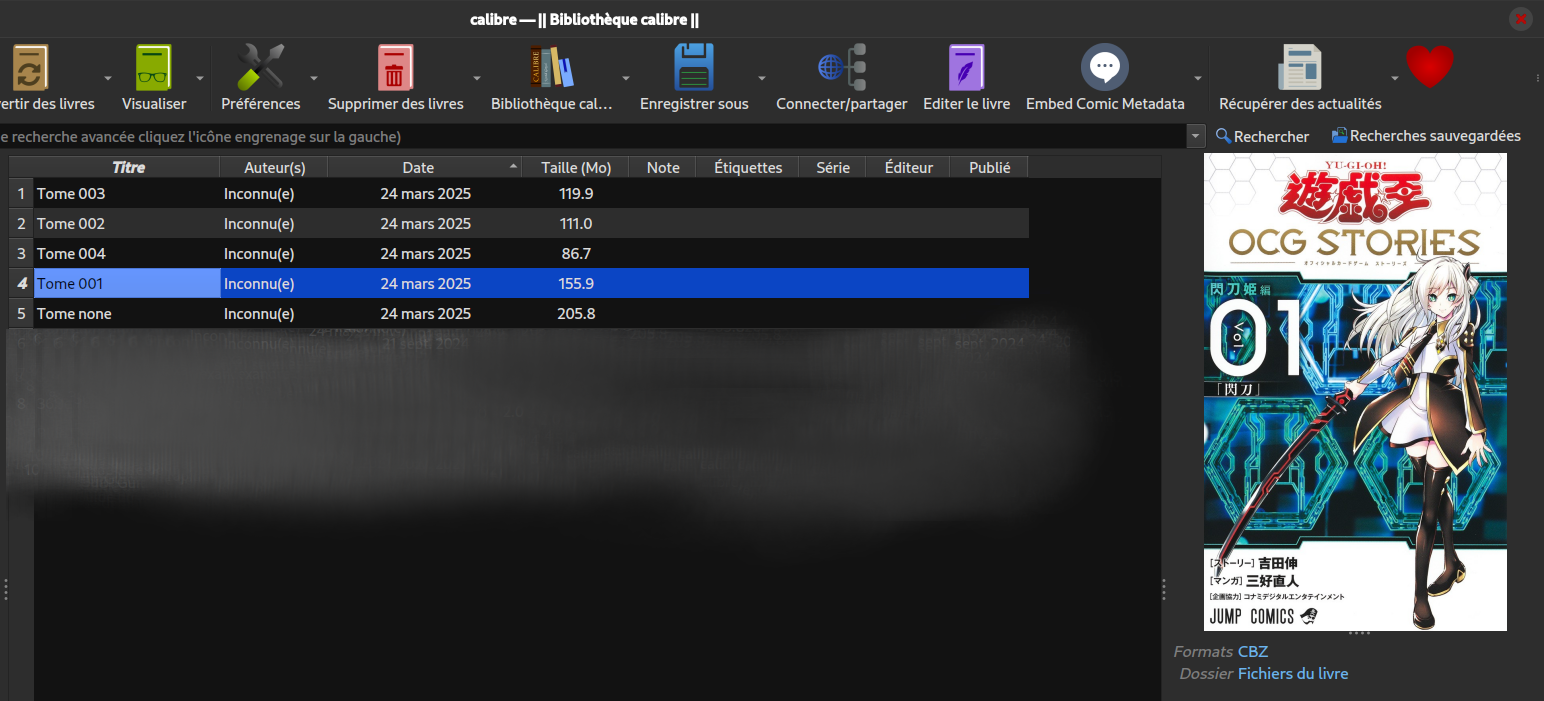
Contrairement à ce que je pensais, et malgré quelques manipulations hasardeuses, Calibre n'a jamais voulu prendre en compte les fichiers Comicinfo.xml… Tant pis… En tout cas ça souligne bien ce que je disais plus haut à mon avis : c'est répandu mais pas standard… 🤷
Donc je vais refaire les métadonnées à la main dans Calibre…
En faire de pdf pour la Kindle
En effet, je reste sur un problème : ma Kindle ne lit toujours pas les fichiers CBZ. Donc il faut que je convertisse les CBZ en PDF pour les lire sur la Kindle.
Là Calibre fait bien le travail que j'attendais (j'avais déjà fait ça dans le passé, donc je savais à quoi m'attendre). Il faut juste penser à bien sélectionner dans l'onglet "Mise en page" le profil de sortie "Kindle Scribe" (évidemment à adapter à votre appareil). Calibre va automatiquement créer des pages au format exact de l'écran de votre appareil en redimensionnant comme il faut pour que le confort de lecture soit optimal.
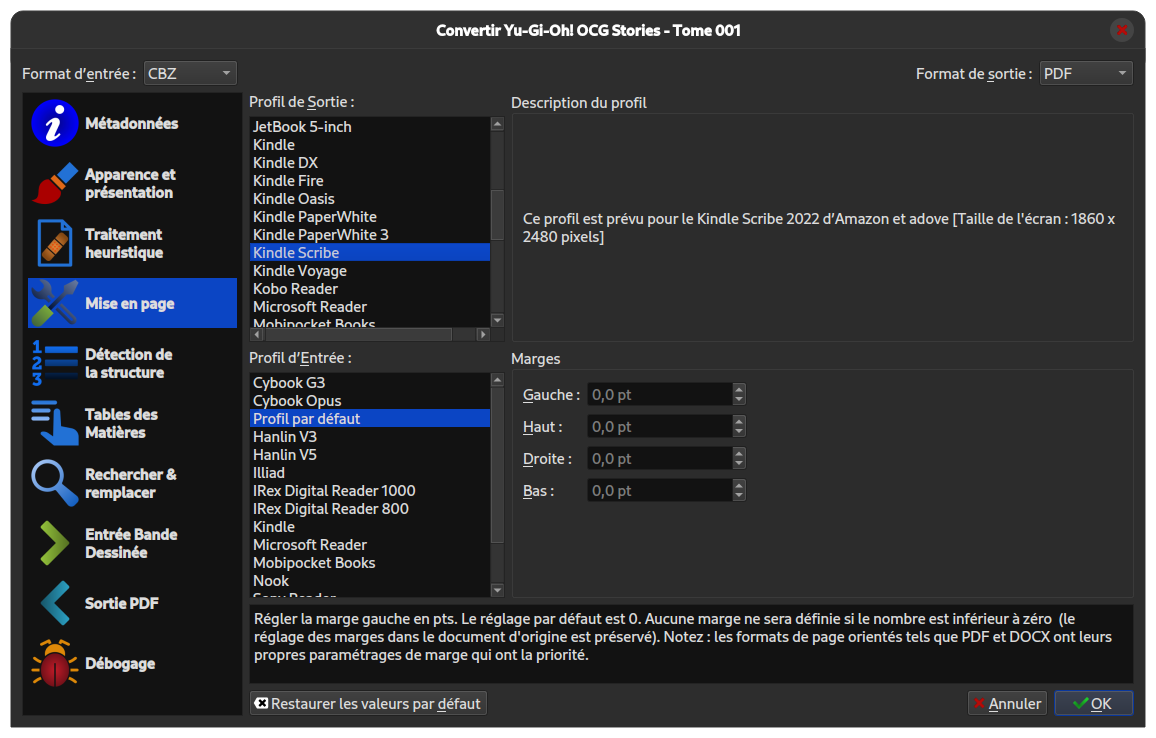
Ensuite quand on ouvre le PDF, on voit que pour la Kindle Scribe, Calibre a ajouté une bande blanche sur les côtés comme les images n'étaient pas aussi larges que l'écran de la Kindle Scribe. Mais sur la Kindle, c'est très propre.



Conclusion
Pour finir je pourrais dire déjà que ça fonctionne assez bien sans être particulièrement compliqué. En vrai j'ai pas mal détaillé et exploré un peu mais en enlevant les fioritures, la manipulation se résume à :
- télécharger les images
- faire des zip
- importer dans Calibre pour les convertir en PF
- copier-coller sur la Kindle
Rien de compliqué, rien qui demande une vraie expertise. Mais je trouvais intéressant de creuser un peu les formats de livres et voir si c'était facile à manipuler ! Et aussi faire un peu de publicité pour Deno (tant qu'à faire !).
Sur ce : je vais lire !
Sources:
- https://calibre-ebook.com/fr
- https://fr.wikipedia.org/wiki/EPUB_(format)
- https://fr.wikipedia.org/wiki/Portable_Document_Format
- https://fr.wikipedia.org/wiki/CBZ_(format_de_fichier)
- https://fr.wikipedia.org/wiki/Comic_book_archive
- https://docs.deno.com/examples/color_logging/
Crédit photo : Générée via Mistral AI avec le prompt suivant
Concevez une image qui représente la transformation de pages de manga en un livre numérique. L'illustration doit montrer une pile de pages de manga éparpillées, avec une liseuse Kindle au centre affichant une page de manga. Ajoutez des éléments technologiques subtils, comme des flèches ou des icônes, pour symboliser le processus de conversion numérique. Utilisez des couleurs vives et un style moderne pour rendre l'image attrayante et dynamique.